“Unlocking Hidden Potential: How AI’s Overlooked Role in Content Creation Could Transform the Future”
We begin with a TL/DR on the NY Times article:
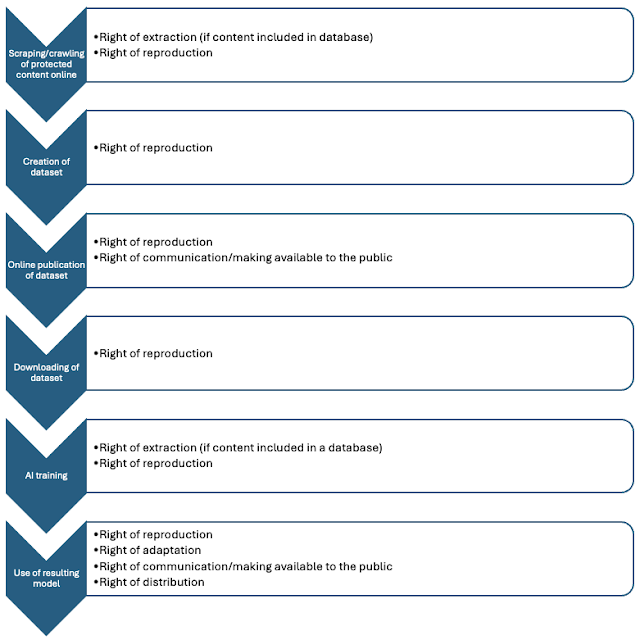
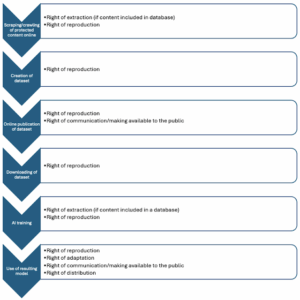
- AI was trained by copying massive amounts of content from online sources without the consent of the content owners. Content owners are now taking various steps to prevent/object to those activities in the absence of a license. This is harmful to, especially, non-profit researchers and smaller AI startups as the data disappears.
Wow. First, let’s get this out of the way. Data is not disappearing and did not do so in 2024. It is still there, with more being created every day. In 2025, forecasters predict humans will create 175 zetabytes of new data. That’s 175 followed by 21 zeros. What has changed is that creators are now directly expressing the need for consent prior to use. These are very different concepts.