“Unlocking the Future: How AI Rights Could Rewrite the Rules of Humanity According to Visionary Babis Marmanis”

How, from a technology perspective, could a machine “read” this human readable text?
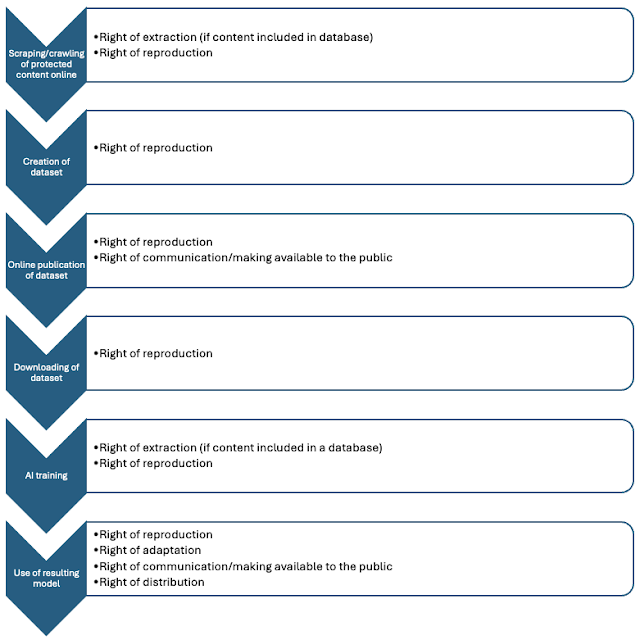
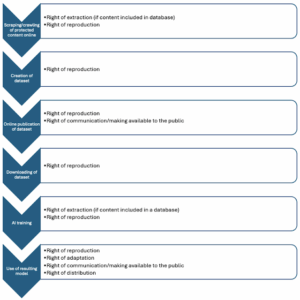
Well, when a crawler visits a page that corresponds to one of its target URLs, it extracts the relevant information from that page, such as the title, the headers, certain keywords, image descriptions, and so on. The crawler could immediately stop processing the page if it identifies the statement “All rights reserved,” which is how a human would know that the content is not available for uses other than the one that they have been permitted to have. Structured data, such as REL based expressions could make that far more specific in terms what is allowed and under what specific terms. But from the perspective of whether you are allowed to process the page or not, even the simplest convention would work. Incidentally, the robots.txt is supposed to indicate exactly what the owner of a page wants you to do with it but it is operating merely as a suggestion, it is entirely up to the crawler whether it will comply to its instructions.